Protected: Students, schools, civil rights, & the f-word
Protected: Students, schools, civil rights, & the f-word Read More »
From Christopher M. Fairman’s “Fuck” (bepress Legal Series: 7 March 2006):
The PTC [Parents Television Council] is a perfect example of the way word taboo is perpetuated. The group’s own irrational word fetish – which they try to then impose on others – fuels unhealthy attitudes toward sex that then furthers the taboo status of the word. See supra notes 119-121 and accompanying text (describing this taboo effect). The PTC has even created a pull-down, web-based form that allows people to file an instant complaint with the FCC about specific broadcasts, apparently without regard to whether you actually saw the program or not. See, e.g., FCC Indecency Complaint Form, https://www.parentstv.org/ptc/action/sweeps/main.asp (last visited Feb. 10, 2006) (allowing instant complaints to be filed against episodes of NCIS, Family Guy, and/or The Vibe Awards). This squeaky wheel of a special interest group literally dominates FCC complaints. Consider this data. In 2003, the PTC was responsible for filing 99.86% of all indecency complaints. In 2004, the figure was up to 99.9%.
One group files 99.9% of all complaints about TV content Read More »
From Jared Jacang Maher’s “DIA Conspiracies Take Off” (Denver Westword News: 30 August 2007):
Chris from Indianapolis has heard that the tunnels below DIA [Denver International Airport] were constructed as a kind of Noah’s Ark so that five million people could escape the coming earth change; shaken and earnest, he asks how someone might go about getting on the list.
…
Today, dozens of websites are devoted to the “Denver Airport Conspiracy,” and theorists have even nicknamed the place “Area 52.” Wikipedia presents DIA as a primary example of New World Order symbolism, above the entry about the eyeball/pyramid insignia on the one-dollar bill. And over the past two years, DIA has been the subject of books, articles, documentaries, radio interviews and countless YouTube and forum board postings, all attempting to unlock its mysteries. While the most extreme claim maintains that a massive underground facility exists below the airport where an alien race of reptilian humanoids feeds on missing children while awaiting the date of government-sponsored rapture, all of the assorted theories share a common thread: The key to decoding the truth about DIA and the sinister forces that control our reality is contained within the two Tanguma murals, “In Peace and Harmony With Nature” and “The Children of the World Dream of Peace.”
…
And not all these theorists are Unabomber-like crackpots uploading their hallucinations from basement lairs. Former BBC media personality David Icke, for example, has written twenty books in his quest to prove that the world is controlled by an elite group of reptilian aliens known as the Babylonian Brotherhood, whose ranks include George W. Bush, Queen Elizabeth II, the Jews and Kris Kristofferson. In various writings, lectures and interviews, he has long argued that DIA is one of many home bases for the otherworldly creatures, a fact revealed in the lizard/alien-faced military figure shown in Tanguma’s murals.
“Denver is scheduled to be the Western headquarters of the US New World Order during martial law take over,” Icke wrote in his 1999 book, The Biggest Secret. “Other contacts who have been underground at the Denver Airport claim that there are large numbers of human slaves, many of them children, working there under the control of the reptilians.”
On the other end of the conspiracy spectrum is anti-vaccination activist Dr. Len Horowitz, who believes that global viruses such as AIDS, Ebola, West Nile, tuberculosis and SARS are actually population-control plots engineered by the government. The former dentist from Florida does not speak about 2012 or reptiles — in fact, he sees Icke’s Jewish alien lizards as a Masonic plot to divert observers from the true earthly enemies: remnants of the Third Reich. He even used the mural’s sword-wielding military figure as the front cover of his 2001 book, Death in the Air.
“The Nazi alien symbolizes the Nazi-fascist links between contemporary population controllers and the military-medical-petrochemical-pharmaceutical cartel largely accountable for Hitler’s rise to power,” Horowitz explained in a 2003 interview with BookWire.
…
Although conspiracy theories vary widely, they all share three commonalities. “One is the belief that nothing happens by accident,” [Syracuse University professor Michael Barkun, author of the 2006 book A Culture of Conspiracy] points out. “Another is that everything is connected. And a third is that nothing is as it seems.” [Emphasis added]
…
[Alex] Christopher is a 65-year-old grandmother living in Alabama.
…
Christopher, on the other hand, was open to hearing anything. A man called her and said he had found an elevator at DIA that led to a corridor that led all the way down into a military base that also contained alien-operated concentration camps. She detailed this theory in her next book, Pandora’s Box II…
And the scale of DIA reflected this desire: It was to be the largest, most modern airport in the world. But almost as soon as ground was broken in 1989, problems cropped up. The massive public-works project was encumbered by design changes, difficult airline negotiations, allegations of cronyism in the contracting process, rumors of mismanagement and real troubles with the $700 million (and eventually abandoned) automated baggage system. Peña’s successor, Wellington Webb, was forced to push back the 1993 opening date three times. By the time DIA finally opened in February 1995, the original $1.5 billion cost had grown to $5.2 billion. Three months after that opening, the Congressional Subcommittee on Aviation held a special hearing on DIA in which one member said the Denver airport represented the “worst in government inefficiency, political behind-the-scenes deal-making, and financial mismanagement.” …
And what looked like a gamble in 1995 seems to have paid off for Denver. Today, DIA is considered one of the world’s most efficient, spacious and technologically advanced airports. It is the fifth-busiest in the nation and tenth-busiest in the world, serving some 50 million passengers in 2006.
From Glyn Moody’s “The duplicitous inhabitants of Second Life” (The Guardian: 23 November 2006):
What would happen to business and society if you could easily make a copy of anything – not just MP3s and DVDs, but clothes, chairs and even houses? That may not be a problem most of us will have to confront for a while yet, but the 1.5m residents of the virtual world Second Life are already grappling with this issue.
A new program called CopyBot allows Second Life users to duplicate repeatedly certain elements of any object in the vicinity – and sometimes all of it. That’s awkward in a world where such virtual goods can be sold for real money. When CopyBot first appeared, some retailers in Second Life shut up shop, convinced that their virtual goods were about to be endlessly copied and rendered worthless. Others protested, and suggested that in the absence of scarcity, Second Life’s economy would collapse.
…
Instead of sending a flow of pictures of the virtual world to the user as a series of pixels – something that would be impractical to calculate – the information would be transmitted as a list of basic shapes that were re-created on the user’s PC. For example, a virtual house might be a cuboid with rectangles representing windows and doors, cylinders for the chimney stacks etc.
This meant the local world could be sent in great detail very compactly, but also that the software on the user’s machine had all the information for making a copy of any nearby object. It’s like the web: in order to display a page, the browser receives not an image of the page, but all the underlying HTML code to generate that page, which also means that the HTML of any web page can be copied perfectly. Thus CopyBot – written by a group called libsecondlife as part of an open-source project to create Second Life applications – or something like it was bound to appear one day.
…
Liberating the economy has led to a boom in creativity, just as Rosedale hoped. It is in constant expansion as people buy virtual land, and every day more than $500,000 (£263,000) is spent buying virtual objects. But the downside is that unwanted copying is potentially a threat to the substantial businesses selling virtual goods that have been built up, and a concern for the real-life companies such as IBM, Adidas and Nissan which are beginning to enter Second Life.
Just as it is probably not feasible to stop “grey goo” – the Second Life equivalent of spam, which takes the form of self- replicating objects malicious “griefers” use to gum up the main servers – so it is probably technically impossible to stop copying. Fortunately, not all aspects of an object can be duplicated. To create complex items – such as a virtual car that can be driven – you use a special programming language to code their realistic behaviour. CopyBot cannot duplicate these programs because they are never passed to the user, but run on the Linden Lab’s computers.
As for the elements that you can copy, such as shape and texture, Rosedale explains: “What we’re going to do is add a lot of attribution. You’ll be able to easily see when an object or texture was first created,” – and hence if something is a later copy.
CopyBot copies all sorts of items in Second Life Read More »
From The Economist‘s “The price of online robbery” (24 November 2008):
Bank details are the most popular single item for sale by online fraudsters, according to a new report by Symantec, an internet-security firm. They are also the priciest, perhaps because the average account for which details are offered has a balance of nearly $40,000. Sales of details of credit cards make up some 30% of all goods and services on offer on “underground” servers, and nearly 60% of their value. Cards without security codes (or CVV2 numbers) are harder to exploit, and are usually cheaper.
Online criminals pay the most for bank account details Read More »
From Stephen E. Arnold’s The Google Legacy: How Google’s Internet Search is Transforming Application Software (Infonortics: September 2005):
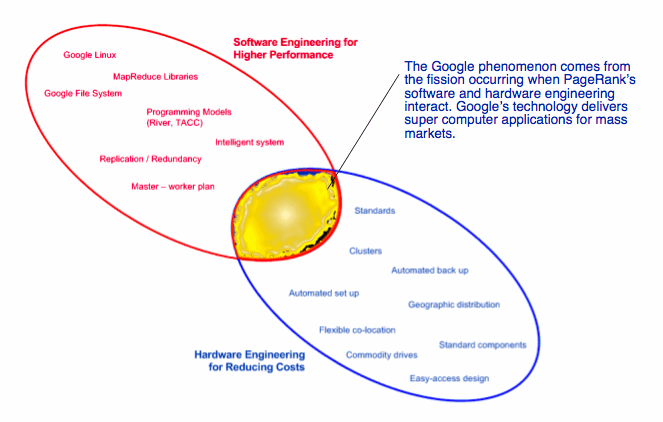
The figure Google’s Fusion: Hardware and Software Engineering shows that Google’s technology framework has two areas of activity. There is the software engineering effort that focuses on PageRank and other applications. Software engineering, as used here, means writing code and thinking about how computer systems operate in order to get work done quickly. Quickly means the sub one-second response times that Google is able to maintain despite its surging growth in usage, applications and data processing.
The other effort focuses on hardware. Google has refined server racks, cable placement, cooling devices, and data center layout. The payoff is lower operating costs and the ability to scale as demand for computing resources increases. With faster turnaround and the elimination of such troublesome jobs as backing up data, Google’s hardware innovations give it a competitive advantage few of its rivals can equal as of mid-2005.
…
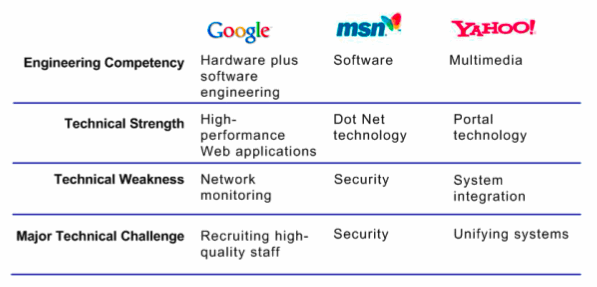
How Google Is Different from MSN and Yahoo
Google’s technologyis simultaneously just like other online companies’ technology, and very different. A data center is usually a facility owned and operated by a third party where customers place their servers. The staff of the data center manage the power, air conditioning and routine maintenance. The customer specifies the computers and components. When a data center must expand, the staff of the facility may handle virtually all routine chores and may work with the customer’s engineers for certain more specialized tasks.
Before looking at some significant engineering differences between Google and two of its major competitors, review this list of characteristics for a Google data center.
1. Google data centers – now numbering about two dozen, although no one outside Google knows the exact number or their locations. They come online and automatically, under the direction of the Google File System, start getting work from other data centers. These facilities, sometimes filled with 10,000 or more Google computers, find one another and configure themselves with minimal human intervention.
2. The hardware in a Google data center can be bought at a local computer store. Google uses the same types of memory, disc drives, fans and power supplies as those in a standard desktop PC.
3. Each Google server comes in a standard case called a pizza box with one important change: the plugs and ports are at the front of the box to make access faster and easier.
4. Google racks are assembled for Google to hold servers on their front and back sides. This effectively allows a standard rack, normally holding 40 pizza box servers, to hold 80.
5. A Google data center can go from a stack of parts to online operation in as little as 72 hours, unlike more typical data centers that can require a week or even a month to get additional resources online.
6. Each server, rack and data center works in a way that is similar to what is called “plug and play.” Like a mouse plugged into the USB port on a laptop, Google’s network of data centers knows when more resources have been connected. These resources, for the most part, go into operation without human intervention.
Several of these factors are dependent on software. This overlap between the hardware and software competencies at Google, as previously noted, illustrates the symbiotic relationship between these two different engineering approaches. At Google, from its inception, Google software and Google hardware have been tightly coupled. Google is not a software company nor is it a hardware company. Google is, like IBM, a company that owes its existence to both hardware and software. Unlike IBM, Google has a business model that is advertiser supported. Technically, Google is conceptually closer to IBM (at one time a hardware and software company) than it is to Microsoft (primarily a software company) or Yahoo! (an integrator of multiple softwares).
Software and hardware engineering cannot be easily segregated at Google. At MSN and Yahoo hardware and software are more loosely-coupled. Two examples will illustrate these differences.
Microsoft – with some minor excursions into the Xbox game machine and peripherals – develops operating systems and traditional applications. Microsoft has multiple operating systems, and its engineers are hard at work on the company’s next-generation of operating systems.
…
Several observations are warranted:
1. Unlike Google, Microsoft does not focus on performance as an end in itself. As a result, Microsoft gets performance the way most computer users do. Microsoft buys or upgrades machines. Microsoft does not fiddle with its operating systems and their subfunctions to get that extra time slice or two out of the hardware.
2. Unlike Google, Microsoft has to support many operating systems and invest time and energy in making certain that important legacy applications such as Microsoft Office or SQLServer can run on these new operating systems. Microsoft has a boat anchor tied to its engineer’s ankles. The boat anchor is the need to ensure that legacy code works in Microsoft’s latest and greatest operating systems.
3. Unlike Google, Microsoft has no significant track record in designing and building hardware for distributed, massively parallelised computing. The mice and keyboards were a success. Microsoft has continued to lose money on the Xbox, and the sudden demise of Microsoft’s entry into the home network hardware market provides more evidence that Microsoft does not have a hardware competency equal to Google’s.
…
Yahoo! operates differently from both Google and Microsoft. Yahoo! is in mid-2005 a direct competitor to Google for advertising dollars. Yahoo! has grown through acquisitions. In search, for example, Yahoo acquired 3721.com to handle Chinese language search and retrieval. Yahoo bought Inktomi to provide Web search. Yahoo bought Stata Labs in order to provide users with search and retrieval of their Yahoo! mail. Yahoo! also owns AllTheWeb.com, a Web search site created by FAST Search & Transfer. Yahoo! owns the Overture search technology used by advertisers to locate key words to bid on. Yahoo! owns Alta Vista, the Web search system developed by Digital Equipment Corp. Yahoo! licenses InQuira search for customer support functions. Yahoo has a jumble of search technology; Google has one search technology.
Historically Yahoo has acquired technology companies and allowed each company to operate its technology in a silo. Integration of these different technologies is a time-consuming, expensive activity for Yahoo. Each of these software applications requires servers and systems particular to each technology. The result is that Yahoo has a mosaic of operating systems, hardware and systems. Yahoo!’s problem is different from Microsoft’s legacy boat-anchor problem. Yahoo! faces a Balkan-states problem.
There are many voices, many needs, and many opposing interests. Yahoo! must invest in management resources to keep the peace. Yahoo! does not have a core competency in hardware engineering for performance and consistency. Yahoo! may well have considerable competency in supporting a crazy-quilt of hardware and operating systems, however. Yahoo! is not a software engineering company. Its engineers make functions from disparate systems available via a portal.
…
The figure below provides an overview of the mid-2005 technical orientation of Google, Microsoft and Yahoo.
The Technology Precepts
… five precepts thread through Google’s technical papers and presentations. The following snapshots are extreme simplifications of complex, yet extremely fundamental, aspects of the Googleplex.
Cheap Hardware and Smart Software
Google approaches the problem of reducing the costs of hardware, set up, burn-in and maintenance pragmatically. A large number of cheap devices using off-the-shelf commodity controllers, cables and memory reduces costs. But cheap hardware fails.
In order to minimize the “cost” of failure, Google conceived of smart software that would perform whatever tasks were needed when hardware devices fail. A single device or an entire rack of devices could crash, and the overall system would not fail. More important, when such a crash occurs, no full-time systems engineering team has to perform technical triage at 3 a.m.
The focus on low-cost, commodity hardware and smart software is part of the Google culture.
…
Logical Architecture
Google’s technical papers do not describe the architecture of the Googleplex as self-similar. Google’s technical papers provide tantalizing glimpses of an approach to online systems that makes a single server share features and functions of a cluster of servers, a complete data center, and a group of Google’s data centers.
…
The collections of servers running Google applications on the Google version of Linux is a supercomputer. The Googleplex can perform mundane computing chores like taking a user’s query and matching it to documents Google has indexed. Further more, the Googleplex can perform side calculations needed to embed ads in the results pages shown to user, execute parallelized, high-speed data transfers like computers running state-of-the-art storage devices, and handle necessary housekeeping chores for usage tracking and billing.
…
When Google needs to add processing capacity or additional storage, Google’s engineers plug in the needed resources. Due to self-similarity, the Googleplex can recognize, configure and use the new resource. Google has an almost unlimited flexibility with regard to scaling and accessing the capabilities of the Googleplex.
…
In Google’s self-similar architecture, the loss of an individual device is irrelevant. In fact, a rack or a data center can fail without data loss or taking the Googleplex down. The Google operating system ensures that each file is written three to six times to different storage devices. When a copy of that file is not available, the Googleplex consults a log for the location of the copies of the needed file. The application then uses that replica of the needed file and continues with the job’s processing.
…
Speed and Then More Speed
…
Google uses commodity pizza box servers organized in a cluster. A cluster is group of computers that are joined together to create a more robust system. Instead of using exotic servers with eight or more processors, Google generally uses servers that have two processors similar to those found in a typical home computer.
Through proprietary changes to Linux and other engineering innovations, Google is able to achieve supercomputer performance from components that are cheap and widely available.
…
… engineers familiar with Google believe that read rates may in some clusters approach 2,000 megabytes a second. When commodity hardware gets better, Google runs faster without paying a premium for that performance gain.
…
Another key notion of speed at Google concerns writing computer programs to deploy to Google users. Google has developed short cuts to programming. An example is Google’s creating a library of canned functions to make it easy for a programmer to optimize a program to run on the Googleplex computer. At Microsoft or Yahoo, a programmer must write some code or fiddle with code to get different pieces of a program to execute simultaneously using multiple processors. Not at Google. A programmer writes a program, uses a function from a Google bundle of canned routines, and lets the Googleplex handle the details. Google’s programmers are freed from much of the tedium associated with writing software for a distributed, parallel computer.
…
Eliminate or Reduce Certain System Expenses
Some lucky investors jumped on the Google bandwagon early. Nevertheless, Google was frugal, partly by necessity and partly by design. The focus on frugality influenced many hardware and software engineering decisions at the company.
…
Drawbacks of the Googleplex
…
The Laws of Physics: Heat and Power 101
…
In reality, no one knows. Google has a rapidly expanding number of data centers. The data center near Atlanta, Georgia, is one of the newest deployed. This state-of-the-art facility reflects what Google engineers have learned about heat and power issues in its other data centers. Within the last 12 months, Google has shifted from concentrating its servers at about a dozen data centers, each with 10,000 or more servers, to about 60 data centers, each with fewer machines. The change is a response to the heat and power issues associated with larger concentrations of Google servers.
The most failure prone components are:
- Fans.
- IDE drives which fail at the rate of one per 1,000 drives per day.
- Power supplies which fail at a lower rate.
Leveraging the Googleplex
…
Google’s technology is one major challenge to Microsoft and Yahoo. So to conclude this cursory and vastly simplified look at Google technology, consider these items:
1. Google is fast anywhere in the world.
2. Google learns. When the heat and power problems at dense data centers surfaced, Google introduced cooling and power conservation innovations to its two dozen data centers.
3. Programmers want to work at Google. “Google has cachet,” said one recent University of Washington graduate.
4. Google’s operating and scaling costs are lower than most other firms offering similar businesses.
5. Google squeezes more work out of programmers and engineers by design.
6. Google does not break down, or at least it has not gone offline since 2000.
7. Google’s Googleplex can deliver desktop-server applications now.
8. Google’s applications install and update without burdening the user with gory details and messy crashes.
9. Google’s patents provide basic technology insight pertinent to Google’s core functionality.
An analysis of Google’s technology, 2005 Read More »
From danah boyd’s “Facebook’s ‘Privacy Trainwreck’: Exposure, Invasion, and Drama” (8 September 2006):
Why does everyone assume that Friends equals friends? Here are some of the main reasons why people friend other people on social network sites:
1. Because they are actual friends
2. To be nice to people that you barely know (like the folks in your class)
3. To keep face with people that they know but don’t care for
4. As a way of acknowledging someone you think is interesting
5. To look cool because that link has status
6. (MySpace) To keep up with someone’s blog posts, bulletins or other such bits
7. (MySpace) To circumnavigate the “private” problem that you were forced to use cuz of your parents
8. As a substitute for bookmarking or favoriting
9. Cuz it’s easier to say yes than no if you’re not sure
Why people “friend” others on social networks Read More »
From Richard Stallman’s “Transcript of Richard Stallman at the 4th international GPLv3 conference; 23rd August 2006” (FSF Europe: 23 August 2006):
Anyway, the term “intellectual property” is a propaganda term which should never be used, because merely using it, no matter what you say about it, presumes it makes sense. It doesn’t really make sense, because it lumps together several different laws that are more different than similar.
For instance, copyright law and patent law have a little bit in common, but all the details are different and their social effects are different. To try to treat them as they were one thing, is already an error.
To even talk about anything that includes copyright and patent law, means you’re already mistaken. That term systematically leads people into mistakes. But, copyright law and patent law are not the only ones it includes. It also includes trademark law, for instance, which has nothing in common with copyright or patent law. So anyone talking about “quote intellectual property unquote”, is always talking about all of those and many others as well and making nonsensical statements.
So, when you say that you especially object to it when it’s used for Free Software, you’re suggesting it might be a little more legitimate when talking about proprietary software. Yes, software can be copyrighted. And yes, in some countries techniques can be patented. And certainly there can be trademark names for programs, which I think is fine. There’s no problem there. But these are three completely different things, and any attempt to mix them up – any practice which encourages people to lump them together is a terribly harmful practice. We have to totally reject the term “quote intellectual property unquote”. I will not let any excuse convince me to accept the meaningfulness of that term.
When people say “well, what would you call it?”, the answer is that I deny there is an “it” there. There are three, and many more, laws there, and I talk about these laws by their names, and I don’t mix them up.
Richard Stallman on why “intellectual property” is a misnomer Read More »
From Richard Stallman’s “Transcript of Richard Stallman at the 4th international GPLv3 conference; 23rd August 2006” (FSF Europe: 23 August 2006):
I hope to see all proprietary software wiped out. That’s what I aim for. That would be a World in which our freedom is respected. A proprietary program is a program that is not free. That is to say, a program that does respect the user’s essential rights. That’s evil. A proprietary program is part of a predatory scheme where people who don’t value their freedom are drawn into giving it up in order to gain some kind of practical convenience. And then once they’re there, it’s harder and harder to get out. Our goal is to rescue people from this.
Richard Stallman on proprietary software Read More »
From Richard Stallman’s “Transcript of Richard Stallman at the 4th international GPLv3 conference; 23rd August 2006” (FSF Europe: 23 August 2006):
Specifically, this refers to four essential freedoms, which are the definition of Free Software.
Freedom zero is the freedom to run the program, as you wish, for any purpose.
Freedom one is the freedom to study the source code and then change it so that it does what you wish.
Freedom two is the freedom to help your neighbour, which is the freedom to distribute, including publication, copies of the program to others when you wish.
Freedom three is the freedom to help build your community, which is the freedom to distribute, including publication, your modified versions, when you wish.
These four freedoms make it possible for users to live an upright, ethical life as a member of a community and enable us individually and collectively to have control over what our software does and thus to have control over our computing.
Richard Stallman on the 4 freedoms Read More »
From Mark Gibbs’ “Debt collectors mining your secrets” (Network World: 19 June 2008):
[Bud Hibbs, a consumer advocate] told me any debt collection company has access to an incredible amount of personal data from hundreds of possible sources and the motivation to mine it.
What intrigued me after talking with Hibbs was how the debt collection business works. It turns out pretty much anyone can set up a collections operation by buying a package of bad debts for around $40,000, hiring collectors who will work on commission, and applying for the appropriate city and state licenses. Once a company is set up it can buy access to Axciom and Experian and other databases and start hunting down defaulters.
So, here we have an entire industry dedicated to buying, selling and mining your personal data that has been derived from who knows where. Even better, because the large credit reporting companies use a lot of outsourcing for data entry, much of this data has probably been processed in India or Pakistan where, of course, the data security and integrity are guaranteed.
Hibbs points out that, with no prohibitions on sending data abroad and with the likes of, say, the Russian mafia being interested in the personal information, the probability of identity theft from these foreign data centers is enormous.
Debt collection business opens up huge security holes Read More »
From Adam Engst’s “Slim down your PDFs” (Macworld: 5 November 2008):
Though few people realize this, you can reduce the size of PDF files using the Leopard version of Preview. To shrink a PDF file, open it in Preview, choose Save As from the File menu, and, in the Save dialog box, choose Reduce File Size from the Quartz Filter pop-up menu. If when you compare the compressed PDF with your original, the images are too fuzzy for your needs (the default settings are pretty severe), you can make your own Quartz filter with different settings.
To do this, launch ColorSync Utility (in Applications/Utilities), choose New Utility Window from the File menu if none is showing, and click on Filters in the toolbar. Click on the arrow to the right of Reduce File Size, choose Duplicate Filter from the drop-down menu, and name your new filter. Enter different values for Image Sampling and Image Compression, switch back to your original PDF in Preview, and save a PDF with your new filter in place of Reduce File Size. With some trial and error, you should be able to arrive at a compromise that satisfies you.
Mac OS X settings to reduce PDF sizes Read More »
From Ian Urbina’s “High Turnout May Add to Problems at Polling Places” (The New York Times: 3 November 2008):
Two-thirds of voters will mark their choice with a pencil on a paper ballot that is counted by an optical scanning machine, a method considered far more reliable and verifiable than touch screens. But paper ballots bring their own potential problems, voting experts say.
The scanners can break down, leading to delays and confusion for poll workers and voters. And the paper ballots of about a third of all voters will be counted not at the polling place but later at a central county location. That means that if a voter has made an error — not filling in an oval properly, for example, a mistake often made by the kind of novice voters who will be flocking to the polls — it will not be caught until it is too late. As a result, those ballots will be disqualified.
…
About a fourth of voters will still use electronic machines that offer no paper record to verify that their choice was accurately recorded, even though these machines are vulnerable to hacking and crashes that drop votes. The machines will be used by most voters in Indiana, Kentucky, Pennsylvania, Tennessee, Texas and Virginia. Eight other states, including Georgia, Maryland, New Jersey and South Carolina, will use touch-screen machines with no paper trails.
…
Florida has switched to its third ballot system in the past three election cycles, and glitches associated with the transition have caused confusion at early voting sites, election officials said. The state went back to using scanned paper ballots this year after touch-screen machines in Sarasota County failed to record any choice for 18,000 voters in a fiercely contested House race in 2006.
Voters in Colorado, Tennessee, Texas and West Virginia have reported using touch-screen machines that at least initially registered their choice for the wrong candidate or party.
…
Most states have passed laws requiring paper records of every vote cast, which experts consider an important safeguard. But most of them do not have strong audit laws to ensure that machine totals are vigilantly checked against the paper records.
…
In Ohio, Secretary of State Jennifer Brunner sued the maker of the touch-screen equipment used in half of her state’s 88 counties after an investigation showed that the machines “dropped” votes in recent elections when memory cards were uploaded to computer servers.
…
A report released last month by several voting rights groups found that eight of the states using touch-screen machines, including Colorado and Virginia, had no guidance or requirement to stock emergency paper ballots at the polls if the machines broke down.
More problems with voting, election 2008 Read More »
From Kevin Poulsen’s “Teenage Hacker Is Blind, Brash and in the Crosshairs of the FBI” (Wired: 29 February 2008):
At 4 in the morning of May 1, 2005, deputies from the El Paso County Sheriff’s Office converged on the suburban Colorado Springs home of Richard Gasper, a TSA screener at the local Colorado Springs Municipal Airport. They were expecting to find a desperate, suicidal gunman holding Gasper and his daughter hostage.
“I will shoot,” the gravely voice had warned, in a phone call to police minutes earlier. “I’m not afraid. I will shoot, and then I will kill myself, because I don’t care.”
But instead of a gunman, it was Gasper himself who stepped into the glare of police floodlights. Deputies ordered Gasper’s hands up and held him for 90 minutes while searching the house. They found no armed intruder, no hostages bound in duct tape. Just Gasper’s 18-year-old daughter and his baffled parents.
A federal Joint Terrorism Task Force would later conclude that Gasper had been the victim of a new type of nasty hoax, called “swatting,” that was spreading across the United States. Pranksters were phoning police with fake murders and hostage crises, spoofing their caller IDs so the calls appear to be coming from inside the target’s home. The result: police SWAT teams rolling to the scene, sometimes bursting into homes, guns drawn.
Now the FBI thinks it has identified the culprit in the Colorado swatting as a 17-year-old East Boston phone phreak known as “Li’l Hacker.” Because he’s underage, Wired.com is not reporting Li’l Hacker’s last name. His first name is Matthew, and he poses a unique challenge to the federal justice system, because he is blind from birth.
…
Interviews by Wired.com with Matt and his associates, and a review of court documents, FBI reports and audio recordings, paints a picture of a young man with an uncanny talent for quick telephone con jobs. Able to commit vast amounts of information to memory instantly, Matt has mastered the intricacies of telephone switching systems, while developing an innate understanding of human psychology and organization culture — knowledge that he uses to manipulate his patsies and torment his foes.
…
Matt says he ordered phone company switch manuals off the internet and paid to have them translated into Braille. He became a regular caller to internal telephone company lines, where he’d masquerade as an employee to perform tricks like tracing telephone calls, getting free phone features, obtaining confidential customer information and disconnecting his rivals’ phones.
It was, relatively speaking, mild stuff. The teen though, soon fell in with a bad crowd. The party lines were dominated by a gang of half-a-dozen miscreants who informally called themselves the “Wrecking Crew” and “The Cavalry.”
…By then, Matt’s reputation had taken on a life of its own, and tales of some of his hacks — perhaps apocryphal — are now legends. According to Daniels, he hacked his school’s PBX so that every phone would ring at once. Another time, he took control of a hotel elevator, sending it up and down over and over again. One story has it that Matt phoned a telephone company frame room worker at home in the middle of the night, and persuaded him to get out of bed and return to work to disconnect someone’s phone.
Matthew, the blind phone phreaker Read More »
From Clay Shirky’s “The Siren Song of Luddism” (Britannica Blog: 19 June 2007):
…any technology that fixes a problem … threatens the people who profit from the previous inefficiency. However, Gorman omits mentioning the Luddite response: an attempt to halt the spread of mechanical looms which, though beneficial to the general populace, threatened the livelihoods of King Ludd’s band.
… printing was itself enormously disruptive, and many people wanted veto power over its spread as well. Indeed, one of the great Luddites of history (if we can apply the label anachronistically) was Johannes Trithemius, who argued in the late 1400s that the printing revolution be contained, in order to shield scribes from adverse effects.
…
The uncomfortable fact is that the advantages of paper have become decoupled from the advantages of publishing; a big part of preference for reading on paper is expressed by hitting the print button. As we know from Lyman and Varian’s “How Much Information?” study, “the vast majority of original information on paper is produced by individuals in office documents and postal mail, not in formally published titles such as books, newspapers and journals.”
…
The problems with e-books are that they are not radical enough: they dispense with the best aspect of books (paper as a display medium) while simultaneously aiming to disable the best aspects of electronic data (sharability, copyability, searchability, editability.)
…
If we gathered every bit of output from traditional publishers, we could line them up in order of vulnerability to digital evanescence. Reference works were the first to go — phone books, dictionaries, and thesauri have largely gone digital; the encyclopedia is going, as are scholarly journals. Last to go will be novels — it will be some time before anyone reads One Hundred Years of Solitude in any format other than a traditionally printed book. Some time, however, is not forever. The old institutions, and especially publishers and libraries, have been forced to use paper not just for display, for which is it well suited, but also for storage, transport, and categorization, things for which paper is completely terrible. We are now able to recover from those disadvantages, though only by transforming the institutions organized around the older assumptions.
Luddites and e-books Read More »
From Timothy Burke’s “The Cookie Monster Economy and ‘Guild Socialism’” (Terra Nova: 2 May 2008):
Mechanisms of exchange have evolved in graphical, commercial virtual worlds from some remarkably crude beginnings. Veterans of the early days of the first Asheron’s Call may remember that at one point, there was no mechanic for secure trade between players. You could hand someone else an item, and then wait and hope for payment in kind. Players responded to that certainty by trying to improvise a reputational culture, including players who built reputations as a trustworthy mobile escrow (both players in a trade would hand their items to the escrow player)., who would then verify that the trade met both of their expectations and distribute the items to their new owners.
Asheron’s Call had no mechanism for secure trade between players Read More »